资料
https://github.com/burpheart/yuque-crawl ,
限制:这个代码只能下载公开的仓库的 md 文件
特点:可以下载别人的公开知识库,可以识别到分组
yuque-helper/yuque2book :已测不能运行atian25/yuque-exporter :已测不能运行瓦雀:https://karobben.github.io/2021/03/02/Python/yuqueAPI/
语雀官方 API:https://www.yuque.com/yuque/developer
教程 获取语雀 Token 网页端登陆语雀—点击头像—账户设置—Token
说明
语雀所有的开放 API 都需要 Token 验证之后才能访问
你需要在请求的 HTTP Headers 传入 X-Auth-Token 带入您的身份 Token 信息,用于完成认证
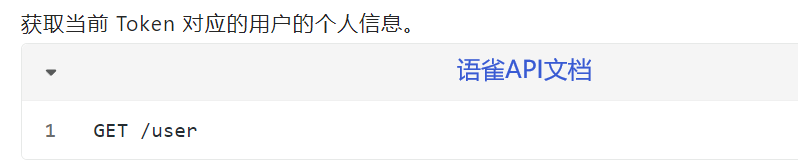
获取用户信息
1 2 3 4 5 6 7 import requestsUSER = "xdd1997" url_user = 'https://www.yuque.com/api/v2/users' header = {"X-Auth-Token" : "your Token" } resu = requests.get(url_user, headers = header).json() resu
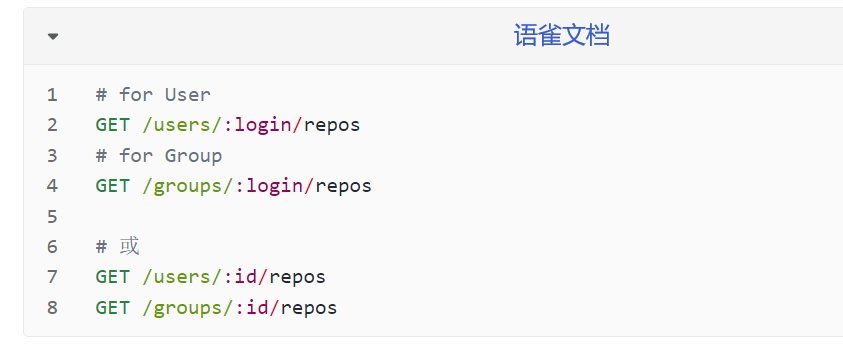
获取用户/团队名下仓库列表
1 2 3 url_repo = 'https://www.yuque.com/api/v2/users/' + USER + "/repos" Repo_Result = requests.get(url_repo, headers = header).json()['data' ] Repo_Result
1 2 3 4 5 6 repo_ids = [] for item in Repo_Result: repo_ids.append(item["id" ]) repo_ids
[4240****, 2120****, 1087****]
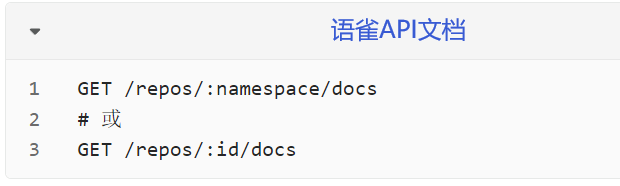
获得一个仓库下的文档列表
1 2 3 4 repo_id = '4240****' url_docs = 'https://www.yuque.com/api/v2/repos/' + repo_id +'/docs' Doc_Result = requests.get(url_docs, headers = header).json()['data' ] Doc_Result
获得一个仓库下所有文档的 slug 1 2 3 4 5 slugs = [] for item in Doc_Result: slugs.append(item['slug' ]) slugs
获取单篇文档信息
1 2 3 4 slug = "gbhna********" url = f"https://www.yuque.com/api/v2/repos/{repo_id} /docs/{slug} " Repo_Result = requests.get(url, headers = header).json() Repo_Result
获取某一篇文档内容 1 2 resu = Repo_Result["data" ]["body" ] resu
1 2 3 4 5 6 7 8 9 '--- title: Python导出语雀文档 categories: [Python] tags: [Python,语雀] date: 2023-10-24 updated: 2023-10-24 cover: https://mypic2016.oss-cn-beijing.aliyuncs.com/picGo/202310241331546.png ---\n\n\n\n## 方法1\n\n1. 代码来源:[https://github.com/burpheart/yuque-crawl](https://github.com/burpheart/yuque-crawl)\n2. 限制:这个代码只能下载公开的仓库的md文件\n3. 根据自己需要,稍稍修改了下以便能下载自己指定的一些仓库,得到下面代码:\n```python\n# BY @burpheart\n# https://www.yuque.com/burpheart/phpaudit\n# https://github.com/burpheart\nimport sys\n\nimport requests\nimport json\nimport re\nimport os\nimport urllib.parse\n\ntset = []\n\n\ndef save_page(book_id, sulg, path):\n docsdata = requests.get(\n \'https://www.yuque.com/api/docs/\' + sulg + \'?book_id=\' + book_id + \'&merge_dynamic_data=false&mode=markdown\')\n if (docsdata.status_code != 200):\n print("文档下载失败 页面可能被删除 ", book_id, sulg,path, docsdata.content)\n return\n docsjson = json.loads(docsdata.content)\n\n f = open(path, \'w\', encoding=\'utf-8\')\n f.write(docsjson[\'data\'][\'sourcecode\'])\n f.close()\n\n\ndef get_book(url, save_path):\n docsdata = requests.get(url)\n data = re.findall(r"decodeURIComponent\\(\\"(.+)\\"\\)\\);", docsdata.content.decode(\'utf-8\'))\n docsjson = json.loads(urllib.parse.unquote(data[0]))\n test = []\n list = {}\n temp = {}\n md = ""\n table = str.maketrans(\'\\/:*?"<>|\' + "\\n\\r", "___________")\n prename = ""\n if (os.path.exists(save_path + "/" + str(docsjson[\'book\'][\'id\'])) == False):\n os.makedirs(save_path + "/" + str(docsjson[\'book\'][\'id\']))\n\n for doc in docsjson[\'book\'][\'toc\']:\n if (doc[\'type\'] == \'TITLE\' or doc[\'child_uuid\']!= \'\'):\n filename = \'\'\n list[doc[\'uuid\']] = {\'0\': doc[\'title\'], \'1\': doc[\'parent_uuid\']}\n uuid = doc[\'uuid\']\n temp[doc[\'uuid\']] = \'\'\n while True:\n if (list[uuid][\'1\'] != \'\'):\n if temp[doc[\'uuid\']] == \'\':\n temp[doc[\'uuid\']] = doc[\'title\'].translate(table)\n else:\n temp[doc[\'uuid\']] = list[uuid][\'0\'].translate(table) + \'/\' + temp[doc[\'uuid\']]\n uuid = list[uuid][\'1\']\n else:\n temp[doc[\'uuid\']] = list[uuid][\'0\'].translate(table) + \'/\' + temp[doc[\'uuid\']]\n break\n if ((os.path.exists(save_path + "/" + str(docsjson[\'book\'][\'id\']) + \'/\' + temp[doc[\'uuid\']])) == False):\n os.makedirs(save_path + "/" + str(docsjson[\'book\'][\'id\']) + \'/\' + temp[doc[\'uuid\']])\n if (temp[doc[\'uuid\']].endswith("/")):\n md += "## " + temp[doc[\'uuid\']][:-1] + "\\n"\n else:\n md += " " * (temp[doc[\'uuid\']].count("/") - 1) + "* " + temp[doc[\'uuid\']][\n temp[doc[\'uuid\']].rfind("/") + 1:] + "\\n"\n if (doc[\'url\'] != \'\'):\n if doc[\'parent_uuid\'] != "":\n if (temp[doc[\'parent_uuid\']].endswith("/")):\n md += " " * temp[doc[\'parent_uuid\']].count("/") + "* [" + doc[\'title\'] + "](" + urllib.parse.quote(\n temp[doc[\'parent_uuid\']] + "/" + doc[\'title\'].translate(table) + \'.md\') + ")" + "\\n"\n else:\n md += " " * temp[doc[\'parent_uuid\']].count("/") + "* [" + doc[\'title\'] + "](" + urllib.parse.quote(\n temp[doc[\'parent_uuid\']] + "/" + doc[\'title\'].translate(table) + \'.md\') + ")" + "\\n"\n\n save_page(str(docsjson[\'book\'][\'id\']), doc[\'url\'],\n save_path + "/" + str(docsjson[\'book\'][\'id\']) + \'/\' + temp[doc[\'parent_uuid\']] + "/" + doc[\n \'title\'].translate(table) + \'.md\')\n else:\n md += " " + "* [" + doc[\'title\'] + "](" + urllib.parse.quote(\n doc[\'title\'].translate(table) + \'.md\') + ")" + "\\n"\n save_page(str(docsjson[\'book\'][\'id\']), doc[\'url\'],\n save_path + "/" + str(docsjson[\'book\'][\'id\']) + "/" + doc[\n \'title\'].translate(table) + \'.md\')\n f = open(save_path + "/" + str(docsjson[\'book\'][\'id\']) + \'/\' + "/SUMMARY.md", \'w\', encoding=\'utf-8\')\n f.write(md)\n f.close()\n\n\nif __name__ == \'__main__\':\n repos ={"CAD_CAE":"cadcae",\n "编程语言":"program",\n "博客文章-公开": "blog"}\n\n for key, value in repos.items():\n url = f"https://www.yuque.com/xdd1997/{value}"\n save_path = f"xdd1997/{key}"\n get_book(url, save_path)\n print(f"{key}下载完成")\n \n```\n\n\n## 方法二\n希望能找到一种可以下载private仓库的方法 已测试不能运行的库\n\n- [yuque-helper/yuque2book](https://github.com/yuque-helper/yuque2book)\n- [atian25/yuque-exporter](https://github.com/atian25/yuque-exporter)\n\n\n\n## 方法三\n参考: [https://karobben.github.io/2021/03/02/Python/yuqueAPI/](https://karobben.github.io/2021/03/02/Python/yuqueAPI/)\n\n'
保存文档内容为 md 文件 1 2 with open (fil_path, "w" , encoding="utf-8" ) as fw: fw.write(resu)
案例 下载语雀所有 Book 的所有文章 TODO: 分组功能需要学习获取知识库目录
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 import osimport shutilimport reimport requestsdef deal_yuque_md (content ): """ 处理语雀一篇文档body中的内容 """ p1 = re.compile (r'' ) resu = p1.findall(content) if len (resu)>0 : for str_ii in resu: content = content.replace(str_ii, "" ) p2 = re.compile (r'!\[.*\]\(.*\)' ) resu = p2.findall(content) if len (resu) > 0 : url_more_list = [] for str_ii in resu: pat = re.compile (r"\(.*\)" ) resu3 = pat.findall(str_ii) if len (resu3)>0 : pat = re.compile (r"#.*\)" ) resu4 = pat.findall(resu3[0 ]) if len (resu4)>0 : url_more_list.append(resu4[0 ]) for kk in url_more_list: content = content.replace(kk, ")" ) return content def login_get_doc (yuque_token ): """ 获取语雀文档链接 Args: yuque_token: 从yuque.com处获得的token Returns: info: 字典形式,返回header.仓库列表.所有文档链接 """ url_user = 'https://www.yuque.com/api/v2/user' header = {"X-Auth-Token" : yuque_token} resu = requests.get(url_user, headers=header).json() user_name = resu["data" ]["login" ] url_repo = 'https://www.yuque.com/api/v2/users/' + user_name + "/repos" Repo_Result = requests.get(url_repo, headers=header).json()['data' ] article_url_list = [] for item in Repo_Result: if item['type' ] == "Book" : repo_id = item['id' ] url_docs = 'https://www.yuque.com/api/v2/repos/' + str (repo_id) + '/docs' Doc_Result = requests.get(url_docs, headers=header).json()['data' ] for ii in Doc_Result: slug = ii['slug' ] url = f"https://www.yuque.com/api/v2/repos/{repo_id} /docs/{slug} " article_url_list.append(url) info = {"header" :header, "Repo_Result" :Repo_Result, "article_url_list" :article_url_list } return info def download_all_doc (info, doc_download_path ): """创建文件夹并下载文章""" header = info["header" ] Repo_Result = info["Repo_Result" ] article_url_list = info["article_url_list" ] table = str .maketrans('\/:*?"<>|' + "\n\r" , "___________" ) if os.path.exists(doc_download_path): shutil.rmtree(doc_download_path) for item in Repo_Result: if item['type' ] == "Book" : repo_name = item['name' ].translate(table) path_repo = os.path.join(doc_download_path, repo_name) if not os.path.exists(path_repo): os.makedirs(path_repo) count_sum = 0 for item in Repo_Result: if item['type' ] == "Book" : url_docs = 'https://www.yuque.com/api/v2/repos/' + str (item['id' ]) + '/docs' Doc_Result = requests.get(url_docs, headers=header).json()['data' ] count_sum = count_sum + len (Doc_Result) count = 0 for url in article_url_list: count += 1 single_doc = requests.get(url, headers=header).json() article_title = single_doc["data" ]["title" ].translate(table) article_body = single_doc["data" ]["body" ] repo_name = single_doc["data" ]["book" ]["name" ].translate(table) print (f"正在下载文章:{count} /{count_sum} :{repo_name} /{article_title} " ) fil_path = os.path.join(doc_download_path, repo_name, article_title + ".md" ) with open (fil_path, "w" , encoding="utf-8" ) as fw: resu = deal_yuque_md(article_body) fw.write(resu) if __name__ == "__main__" : yuque_token = "***" info = login_get_doc(yuque_token) doc_download_path = r"语雀文章下载位置" download_all_doc(info,doc_download_path)
https://github.com/xie-dd/yuque-book-download.git
修改一篇文章 官方文档
我们的代码 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 import jsonimport requestsif __name__ == "__main__" : """ 获取个人信息 """ yuque_token = "" url = 'https://www.yuque.com/api/v2/user' header = {"X-Auth-Token" : yuque_token} resu = requests.get(url, headers=header).json() user_name = resu["data" ]["login" ] """ 获取仓库信息 """ url = 'https://www.yuque.com/api/v2/users/' + user_name + "/repos" repo = requests.get(url, headers=header).json()['data' ] repo_str = json.dumps(repo, indent=4 ) print (repo_str) """ 更新文章 """ book_id = "48856153" doc_slug = "144301227" url = f"https://www.yuque.com/api/v2/repos/{book_id} /docs/{doc_slug} " my_body = "xdd-xdd-xdd" my_title = "xdd3" data = { "slug" : doc_slug, "title" : my_title, "public" : 1 , "format" : "markdown" , "body" : my_body } responses = requests.put(url, data=data, headers=header) if responses.status_code == 200 : print ("文章更新完成" )
创建一篇文章 官方文档
我们的代码 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 import jsonimport requestsdef check_is_exist (book_id, my_slug ): url = f"https://www.yuque.com/api/v2/repos/{book_id} /docs/{my_slug} " responses = requests.get(url, headers=header) if responses.status_code == 404 : isexist = 0 elif responses.status_code == 200 : isexist = 1 else : raise ValueError("出现错误" ) return isexist if __name__ == "__main__" : """ 获取个人信息 """ yuque_token = "" url = 'https://www.yuque.com/api/v2/user' header = {"X-Auth-Token" : yuque_token} resu = requests.get(url, headers=header).json() user_name = resu["data" ]["login" ] """ 获取仓库信息 """ url = 'https://www.yuque.com/api/v2/users/' + user_name + "/repos" repo = requests.get(url, headers=header).json()['data' ] repo_str = json.dumps(repo, indent=4 ) print (repo_str) """ 发表文章 """ book_id = '48856153' url = f"https://www.yuque.com/api/v2/repos/{book_id} /docs" my_slug = "144301227" my_title = "Python提交的文档27" my_body = "XDD" isexist = check_is_exist(book_id, my_slug) if isexist == 1 : print (" my_slug 已经存在" ) else : data = { "slug" : my_slug, "title" : my_title, "public" : 1 , "format" : "markdown" , "body" : my_body } responses = requests.post(url, data=data, headers=header) if responses.status_code == 200 : print ("文章创建完成" ) """ 将文档添加到知识库目录 """ url = f"https://www.yuque.com/api/v2/repos/{book_id} /docs/{my_slug} " responses = requests.get(url, headers=header) doc_id = responses.json()['data' ]['id' ] url = f"https://www.yuque.com/api/v2/repos/{book_id} " data = { "action" : "appendNode" , "action_mode" : "child" , "type" : "DOC" , "doc_ids" : doc_id, } responses = requests.put(url, data=data, headers=header) if responses.status_code == 200 : print ("文章添加到目录完成" )
可以创建文章,但是不能添加到目录,不知道为啥,如有帮助,请评论告知。








 wechat
wechat alipay
alipay




